nlp_skip-gram_tutorial
Written on July 9th, 2018 by hyeju.kim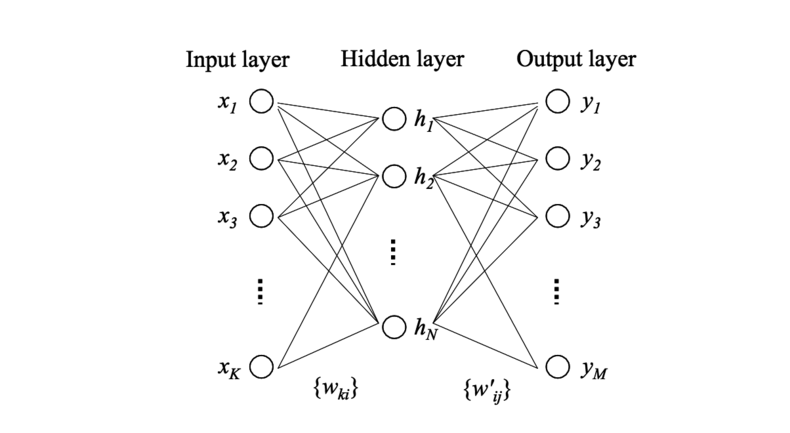
import numpy as np
np.random.seed(20180709)
포스트 앞부분은 다음 사이트를 참고하였습니다. http://adventuresinmachinelearning.com/word2vec-tutorial-tensorflow/ 이사이트에서는 텐서플로우로 구현해놨는데 (softmax skip-gram 까지) 좀 더 실용적, 전문적
뒷부분은 다음 사이트 참고(행렬 예제 부분) https://districtdatalabs.silvrback.com/nlp-research-lab-part-3-forward-propagation-1
Word2Vec word-embedding
워드투벡 임베딩은 우리가 텍스트를 학습시키기 위해 벡터 형태로 표시할 때 쓰인다.
one-hot encoding은 단순히 단어들을 (1,0,0,0,..,0) 형태로 나타내는데, 이는 벡터들간의 의미를 담기 어렵고, 단어들간의 유사도 거리를 나타내기도 어렵다. 차원이 커지면 의미에 차이가 있더라도 벡터들간의 거리는 근소한 차이밖에 나지 않기 때문이다. 이를 보완한 것이 word2vec 임베딩이다.
word2vec 임베딩은 크게 두가지의 역할을 한다. 첫째, 매우 큰 차원의 행렬을 좀 더 낮은 차원의 행렬로 바꿔준다. 즉, 맨 처음 원핫인코딩으로 커진 매트릭스를 더 작은 차원으로 바꿔주는 ‘word embedding’역할이다. 두번째, 그러면서도 단어의 의미를 담기게 한다.
word2vec에는 CBOW(Continuous Bag Of Words)approach와 Skip-gram approach두 가지가 있다. skip-gram은 인풋 단어를 받고 이와 가까운 단어들의 확률을 내보내는 것이다. CBOW는 이와 반대로 먼저 문맥 단어들을 받고 그 문맥에 해당하는 단어를 보여준다.
여기서는 skip-gram model에 관해 간단한 예제를 통해 이해해볼 것이다.
skip gram moldel with matrix example

skip-gram의 간략한 구조
왼쪽 아래 그림을 보며 간단히 설명하자면 먼저
- input layer : input layer에 단어를 집어 넣는다.
- projection layer : 1번의 차원을 축소하여 projection layer에 embedding한다.
- output layer: outputlayer는 input word의 context에 어떤 단어가 나올지 확률로 나타낸다.
1번과 2번 사이, 2번과 3번 사이에는 모두 weight matrix를 사용하여 차원을 축소하거나, 차원을 바꾸어 표현한다.
matrix는 어떻게 만들어지나?
앞에서 말한 weight matrix는 처음부터 정해져 있는게 아니라 backpropagation으로 오류를 줄여가며 만들어가는 것이다. 앞으로 볼 예제에서는 랜덤으로 weight matrix를 만들어서 구조를 파악해볼 것이다.
matrix를 직접 만들면서 이해해보자
1.input layer : input word를 one-hot encoding 으로 표현하여 넣기
예시 문장은 다음과 같다.
" Duct tape works anywhere. Duct tape is magic and should be worshiped.”
데이터를 넣기 전 몇가지 개념에 관해 살펴보자.
1-1. vocabulary(v)
vocabulary 는 주어진 문장에서 unique한 단어들을 모은 list라고 생각하면 된다.
v = ["duct", "tape", "work", "anywher", "magic", "worship"]
1-2. context (c)
context(c)는 target word 앞 뒤로 고려할 문맥의 단어 수라고 생각하면 된다. 여기서는 2개라고 가정하자.
c = 2
1-3. size of projection layer (n)
projection layer는 hidden layer의 다른 말로 생각하면 된다.(skip gram model의 hidden layer은 다른 뉴럴넷과 달리 activation step을 제거했다.) 얼만큼 차원을 줄일건지 생각하면 된다. 예를 들어서 여기는 3으로 지정하자.
n = 3
1-4. word embedding
print(v)
['duct', 'tape', 'work', 'anywher', 'magic', 'worship']
아까 말했던 vocabulary를 one-hot encoding으로 부여하면
“duct” [1,0,0,0,0,0]
“tape” [0,1,0,0,0,0]
“work” [0,0,1,0,0,0]
“anywher” [0,0,0,1,0,0]
“magic” [0,0,0,0,1,0]
“worship” [0,0,0,0,0,1]
tape 는 다음과 같이 표현할 수 있다는 것이다.
input_array_tape=np.array([0,1,0,0,0,0]) #"tape"
1.5. weight matrix p
인풋 레이어의 차원(v)을 projection 레이어의 차원(n)으로 줄여주는 것이 weight matrix 이다. 즉. v x n 차원의 weight matrix 를 가진다.
input_weight_matrix = np.random.random_sample((6,3)) # p = 6, n = 3
print(input_weight_matrix)
[[ 0.08043602 0.84516156 0.72666085]
[ 0.71035494 0.54452636 0.45607399]
[ 0.40217721 0.13365922 0.08037119]
[ 0.93729691 0.44922337 0.17636804]
[ 0.57195901 0.31674591 0.0774984 ]
[ 0.75258631 0.00753526 0.12873297]]
2. projection layer
projection = np.dot(input_array_tape,input_weight_matrix)
print(projection)
[ 0.71035494 0.54452636 0.45607399]
2.5 weight matrIx p’(p’ 는 p와 별개. 독립적. transpose나 그런 관계 아니다.)
weight matrix p’는 projection layer와 output layer를 연결해준다. 만약 context size가 2라면 output layer는 context 4개에 대한 output vector를 보여준다. 즉, t-2, t-1, t+1, t+2 의 context 관계에 있는 vector들에 관해 probability를 보여준다. weight matrix p’는 각각 n x v dimension을 가진다.
output_weight_matrix = np.random.random_sample((3,6))
print(output_weight_matrix)
[[ 0.30124727 0.43874411 0.04917487 0.25379158 0.74816343 0.9877867 ]
[ 0.31662707 0.79523539 0.22687123 0.26891052 0.1822091 0.80747186]
[ 0.92992963 0.18887079 0.66989841 0.85639473 0.42481248 0.36898341]]
3. output layer
input word에 대해 그 주변 맥락으로 어떤 단어가 나타날지 확률로 알려준다.
output_array_for_input_tape_and_t_2 = np.dot(projection, output_weight_matrix)
print(output_array_for_input_tape_and_t_2 )
[ 1.15699126 0.576625 0.79918093 0.71965431 0.64668103 0.6861468 ]
print(list(zip(v, output_array_for_input_tape_and_t_2)))
[('duct', 1.1569912556843316), ('tape', 0.57662499956617397), ('work', 0.7991809253928247), ('anywher', 0.71965430727654456), ('magic', 0.64668102762541735), ('worship', 0.68614680195170008)]
그런데 얘네는 확률의 형태가 아니다. 확률의 형태로 사용하려면 softmax function을 사용하면 되는데 이건 지금 깊게 다룰 게 아니라 넘어가겠다. 궁금하시면 위 참고사이트를 보시길!!
